ETL Process Explained
with Real-World Examples
• April 2026 • 5 min read
Every data-driven company — from Netflix to Amazon — relies on a foundational process to move, clean, and prepare data for analysis. That process is ETL: Extract, Transform, Load. Whether you're building a data warehouse, training an ML model, or powering a dashboard, ETL is the backbone behind it all.
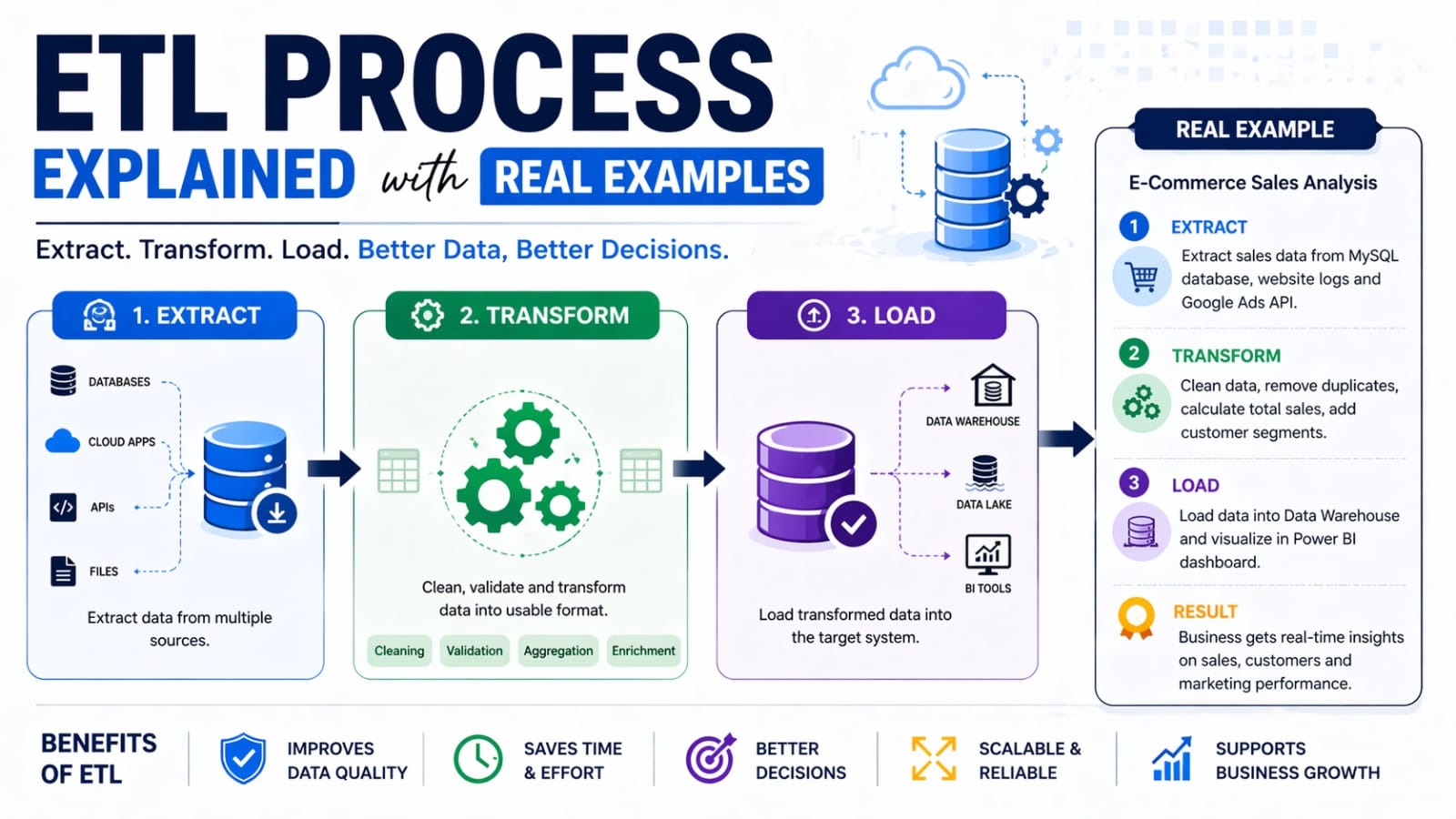
What is ETL? ETL stands for Extract, Transform, Load — a three-stage pipeline for collecting raw data from source systems, cleaning and reshaping it, and storing it in a destination system such as a data warehouse or database. |
The 3 Stages of ETL
Stage | What Happens | Real-World Example |
|---|---|---|
Extract | Pull raw data from source systems (APIs, DBs, files, sensors) | Scraping daily sales from a PostgreSQL database |
Transform | Clean, reshape, and enrich the data to match business rules | Converting date formats, removing nulls, joining tables |
Load | Write the processed data into a target store | Loading cleaned records into Amazon Redshift |
1. Extract — Getting the Raw Data
Extraction is the starting point: pulling data from one or more source systems. Sources can be wildly different — relational databases, REST APIs, CSV files, event streams, IoT sensors, or third-party SaaS tools like Salesforce or Stripe.
Real Example — E-Commerce Order Pipeline An e-commerce company extracts order data from three sources every night at midnight:
|
Key challenges during extraction include handling API rate limits, managing large data volumes efficiently, and ensuring extraction doesn't overload source systems during business hours.
2. Transform — Making Data Useful
Transformation is where the real data engineering work happens. Raw data is rarely clean or consistent. This stage applies business logic to reshape data into a usable format.
Common transformation tasks include:
- Data cleaning — removing duplicates, filling missing values, fixing typos
- Type conversion — parsing strings to dates, integers, decimals
- Normalization — standardizing units, currencies, or text casing
- Aggregation — computing totals, averages, or counts by group
- Joining — merging data from multiple source tables
- Business rule application — e.g., classifying customers as 'high-value' if total spend > ₹50,000
Real Example — Customer Analytics at a Bank A bank's ETL pipeline transforms raw transaction data by:
|
3. Load — Storing the Processed Data
The final stage loads the transformed data into the target system. This is typically a data warehouse (like Snowflake, BigQuery, or Redshift), a data lake (like AWS S3 or Azure Data Lake), or even a production database that powers an application.
There are two loading strategies:
- Full Load — replace all existing data with fresh data each time (simple, but slow for large datasets)
- Incremental Load — only insert or update records that have changed since the last run (efficient, but requires change detection logic)
Real Example — Retail Analytics Dashboard A retail chain loads its nightly ETL output into Google BigQuery. The dashboard team then runs SQL queries on top to power daily sales reports in Looker Studio. The incremental load strategy means only today's transactions are appended — keeping the pipeline fast even with 5 years of historical data. |
ETL vs ELT — What's the Difference?
With modern cloud data warehouses, a new pattern has emerged: ELT (Extract, Load, Transform). Instead of transforming data before loading it, ELT loads raw data first and transforms it inside the warehouse using SQL.
ETL | ELT | |
|---|---|---|
Transform | Before loading | After loading (inside warehouse) |
Best for | Structured, compliance-heavy data | Large-scale, cloud-native analytics |
Tools | Talend, Informatica, Apache Spark | dbt, Fivetran, BigQuery |
Speed | Slower (external compute) | Faster (warehouse compute) |
Popular ETL Tools
The ETL ecosystem is rich. Here are the most widely used tools across different use cases:
- Apache Airflow — open-source workflow orchestrator, widely used in data teams
- Apache Spark — distributed processing for large-scale transformations
- dbt (data build tool) — SQL-based transformations inside warehouses (ELT pattern)
- Fivetran / Airbyte — managed connectors that automate the Extract and Load stages
- Talend / Informatica — enterprise-grade GUI-based ETL platforms
- AWS Glue / Azure Data Factory — cloud-native managed ETL services
Key Takeaways
✅ Summary
|